
Dados são representações de fatos ou convenções. Esse termo acaba sendo tão usado na era da informação exatamente porque a facilidade de armazenar e lidar com essas representações aumenta exponencialmente.
O tratamento de volumes extraordinários de dados começou a ser chamada de “análise de big data”. Esse termo ganhou relevância nos últimos anos, quando críticas com relação à privacidade e outros problemas civis que esse tipo de análise apresentam vieram à tona.

O problema dos dados e do tratamento deles é que as decisões sobre o enfoque de sua análise são (ainda) humanas: os dados brutos dizem muito pouco, e dados tratados de forma incorreta não dizem nada, ou pior, nos levam a cometer erros em termos do mundo real.
No filme Brazil, de Terry Gilliam, uma versão pós-moderna do 1984 de George Orwell, um sujeito inocente é capturado, torturado e morto porque uma mosca cai morta no cabeçote de impressão e uma letra em um nome é trocada. Mas esse é o tipo de erro fortuito que pode acontecer com a “small data”, e que, em termos da big data se torna difuso e menos relevante (não para o sujeito, claro).
Que tipos de problemas específicos em termos de direitos civis podem acontecer com a big data?
O Google e outros gigantes da tecnologia já conquistaram legalmente o privilégio de tratar dados brutos como anônimos: como é um computador que verifica seus padrões de busca por pornografia, por exemplo, e como os resultados que ele obtém são impessoais (isto é, ele não liga o seu nome com aquela busca, depois que a processa), isto não é legalmente considerado quebra de privacidade.
Embora o Google deixe você optar se quer ou não participar desse tipo de colheita de dados, a opção padrão é colaborar com as estatísticas do Google.
A ideia não é nova , mas nesse momento ainda estamos na ponta de iceberg do uso desse tipo de dados. A maioria das pessoas pensa que ele se refere apenas a servir publicidade mais direcionada, ainda que atualmente até mesmo epidemias de gripe possam ser facilmente traçadas por buscas no Google. Se numa determinada área muitas buscas por determinados sintomas surgem, o Google já é capaz de mostrar essa tendência de forma regional. Disso para a “psico-história” de Isaac Asimov, é só um passo.
E não só de análise de buscas vive o big data. A mineração de informação em fóruns e redes sociais, e por toda a web, e principalmente o cruzamento de vastos bancos de dados, tem amplos potenciais ainda pouco explorados. O problema principal quanto à análise destes dados é a falta de profissionais generalistas, quase polímatas, que seriam necessários para desenvolver esses algoritmos.
Conhecimentos de ciências sociais, economia, linguística, são essenciais, além de campos da matemática como teoria dos jogos e estatística, e, é claro, os próprios conhecimentos em ciência da computação que, nesse volume de dados, passam a ser bastante complexos. Se alguém tem essa capacidade, pode muito bem, com apenas dados públicos obtidos pela internet, entender tendências e ganhar muito dinheiro com isso.
Link YouTube | The Landscape of Data Analysis
Aliás, é isso que o investidor amador em ações algumas vezes pensa que fará, o que acaba numa mistura de leitura e interpretação de notícias e loteria. Botar esses dados num algoritmo coerente não é nada fácil.
É bom lembrar que o termo “big data” pode se referir a algo como o projeto genoma, ou o Hadron Collider, que produzem volumes enormes de dados (o único critério para algo ser chamado de big data), e podem não exigir coisas como ciências sociais e economia – mas sim outros conhecimentos especializados –, porém a parte mais interessante, por que também mais problemática, é a da previsão das agências de massas de seres humanos: como votam, como consomem, o que pensam.
E isso exige um cruzamento de exatas e humanas que não é muito usual.
Se por um lado Mitt Romney não parecia mesmo ter muita chance nas últimas eleições nos Estados Unidos, não ajudou o fato de seu sistema de análise de big data e app falharem – e que Barack Obama foi novamente muito eficaz na arrecadação de fundos pela Internet. Essa eleição foi também a primeira demonstração pública da precisão de análise do big data . Nate Silver previu em detalhes e com mínimos erros os resultados, meramente através da análise matemática e o cruzamento de muitas pesquisas e dados de várias fontes.
Desconfiamos, com propriedade, das estatísticas: elas normalmente fazem parte do discurso de desinformação, ao postular tragédias humanas inconcebíveis em termos de “meros dados”. Além disso, podemos querer saber que tipo de chance nosso câncer nos dá, e algo como “70% de chance de sobrevivência após 3 anos do tratamento” é uma informação, dependendo do contexto, apavorante ou tranquilizadora.
Mas, do ponto de vista de um conhecimento livre de emoções, ela nem mesmo não diz muito: ela não diz nada. Nós sempre, como indivíduos, podemos estar na cauda longa dos baixos percentuais – sejam de sobrevivência ou não. Em outras palavras, probabilidade pode ser útil de um ponto de vista prático, ou para tomar decisões (médicas, por exemplo), mas não diz absolutamente nada sobre os fatos.
Esse tipo de dicotomia entre o prático e o teórico é difícil de aceitar quanto a coisas simples como porcentagens ou médias como as que calculamos no ensino médio, que dizer então das vastas decisões sobre que métodos empregar para trabalhar com volumes imensos de dados heterogêneos – e algumas vezes mal coletados ou interpretados. Com a desconfiança que o mercado financeiro hoje nos desperta, com suas máquinas disputando ações em frações de segundo, e decidindo o futuro de blocos inteiros de nações através de algoritmos que talvez nenhum ser humano conheça em sua inteireza, parece fazer sentido olhar esses outros desenvolvimentos também com um pé atrás.
Em outras palavras, quando a coisa funciona ela assusta para o lado dos problemas usuais com direitos civis, privacidade e manipulação das massas; quando não funciona, e conduz ao erro, nos leva em direções inesperadas e pode conduzir a todo tipo de catástrofe.
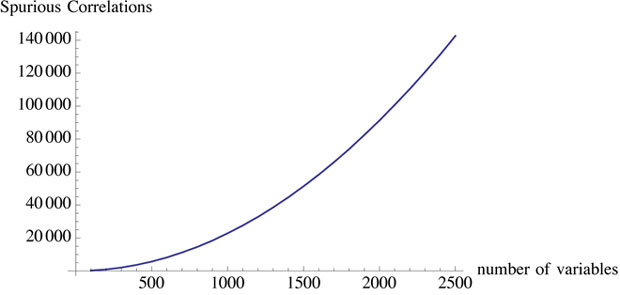
Mas qual seria a diferença entre a big data e os processos de análise usuais, senão maior quantidade e talvez velocidade? Não será esse termo apenas mais uma buzzword do mundo da tecnologia que se mostra vacuosa após um período intenso de uso?
É possível, por outro lado é certo que ainda vamos ver o tratamento de vastas coleções de dados dar resultados surpreendentes, tanto bons quanto ruins.
Num mundo em que o Facebook pode saber que você é gay antes de você mesmo, onde o Google (e a IBM) verifica(m) o que você escreve para não colocar sua empresa numa cilada jurídica e onde o feedback das pesquisas eleitorais retorna direta e matematicamente para as redes sociais – e onde até mesmo a terminologia usada é fruto de um cálculo, temos muito no que prestar atenção.
Talvez demais.
publicado em 15 de Maio de 2013, 07:00



